Performing smooth animation transitions in response to user input is a complicated problem. The user can press any button at any time. You have to check that the character can do the requested move, and depending on currently displayed state, switch to the new animation at exactly the right moment. You also have to track how things have changed, to be ready for the next move of the user.
In all, a rather complicated sequence of checks, actions, and assignments that need to be handled. The sequence quickly runs out of hand with a growing number of moves, game states, and animations. Lots of combinations have to be checked. While writing it once is hard enough, if you have to update or modify it later, finding all the right spots to change without missing one, is the second big problem.
By using state machines, it becomes possible to express precisely what may happen in an orderly way. One state machine only describes the animations and their transitions. A second state machine describes user interaction with the game character, and updates the game character state. By keepinh animation state and game character state separate, things get much easier to understand, and to reason about. Later changes also get simpler as it avoids duplication.
While having such state machines on paper is already quite helpful in understanding, there is also a straight forward implementation path, which means you can plug your state machines into the game, and run them.
This article briefly touches on what state machines are and how they work, before jumping into the topic at hand. If you don't know about state machines, it is probably a good idea to read about them first. The state machines here are somewhat different, but it helps if the state machine concept is not entirely new. The References section below lists some starting points, but there are many more resources available at the all-knowing Internet.
The article concentrates on using state machines for describing allowed behavior, and how the state machines synchronize. While it has an example to demonstrate the ideas, the article does not discuss the environment around the state machines at length. That is, how to make user input and game state available to the state machine condition, or how to start and run animations. The implementation of the synchronizing state machines is also not shown in full detail.
A state machine is a way to describe behavior (activities that are being done for a while), and how you can switch between different activities. Each activity is called a state. Since this is so awfully abstract, let's try to describe your behavior right now. You are currently reading (this text). Reading is a state. It's an activity that you do for a while. Now suppose you get a phone call. You stop reading, and concentrate on the conversation. Talking on the phone is another activity that you do for a while, a second state. Other states of you are Walking, Running, Sleeping, and a lot more.
The activity that you are doing now is special in the description. The state associated with the current activity is called current state (not indicated in the figure). It is a "you are doing this" pointer.
Having states is nice, but so far it's just a list of activities you can do, and a current state, the activity you are doing right now. What is missing, is structure between the states. You can go from Running directly to Sleeping or to any other activity. It is not a very good description of how activities relate. This is where edges come in. Edges define how you can switch from one state to the next. You can see an edge as an arrow, starting at one state, and pointing to the next state. The rule is that you can only change the current state by following an edge from the current state to the state where the edge leads to. The latter state then becomes the new current state (your new activity).
By adding or removing edges between the states, you can influence how the current state can switch between different activities. For example, if you don't have a Running to Sleeping edge, and add a Running to Showering edge and a Showering to Sleeping edge, you can force the current state through the Showering state while going from Running to Sleeping.
You can apply the same ideas to your game character (or your AI character). Game characters are a lot simpler than real world persons to describe. You can see an example below.
This game character can do just four activities. It can stand (on a platform for example), run, jump, and crawl. The edges say how you can change between states. It shows for example, that you have to go from Crawling to Standing to Running. You cannot go directly from Crawling to Running.
Game character states are kind of obvious, but you can use state machines for a lot more. If you see displaying a (single) animation as an 'activity that is being done for a while' (namely showing all the frames one by one until the end of the animation), you can consider displaying an animation to be a state, and switching between animations an edge, and you can draw a diagram like below.
![Attached Image: anim_states.png]()
You have a state for each animation, and the current state here is the animation currently playing. Edges define how you can go from one animation to the next. Since you want smooth animation, you only add edges from one animation to the next, where the animations 'fit' (more on the precise timing of this below, when discussing conditions of edges).
If you compare the character states with the animation states, you see there is a lot of overlap, but not entirely. The Crawling character state has been expanded to Crawl_leftarm_anim (crawling with your left arm on the floor), and Crawl_rightarm_anim (crawling with your right arm on the floor). From the standing animation you always start with Crawl_leftarm_anim, and you can go back and forth between the left arm and right arm animation, thus slowly crawling across the screen. The Jumping character state has also been split, if you run before jumping, you get a different (flying) animation.
Each state machine should only care about its own data. The game character state machine handles user input, and updates game character state; the animations state machine deals with animations, frame rates, and frames. The computer handles synchronization between both state machines, as discussed below.
So far so good. We have a state machine describing how the game character behaves, and we have a state machine describing how to play animation sequences.
Now it would be quite useful if the current state of the game character and the current state of the animations match in some way. It looks very weird if the game character state is Standing, while the current animation displays Running_anim. You want to display the running animation only when the game character state is Running too, display one of the crawling animations when the game character state is Crawling, and so on. In other words, both state machines must be synchronized in some way.
The simplest form of synchronization is fully synchronized on state. In that case, each game character state has one unique animation state. When you change the game character state, you also change the animation state in the same way. In fact, if you have this, the game character state machine and the animation state machine are exactly the same! (The technical term is isomorphic.) You can simply merge both state machines into one, and get a much simpler solution.
However, in the example, full synchronization on state fails. There are two animation states for crawling, and the Fly_anim does not even have a game character state in the example.
What is needed in the example is a bit more flexibility. The animation state machine should for example be allowed to switch between the Crawl_leftarm_anim and Crawl_rightarm_anim animations without bothering the game character state machine about it. Similarly, the Jumping state should not care whether a Fly_anim or Jump_anim is displayed. On the other hand, if you go from Running to Standing in the game character state machine, you do want the animation state machine to go to Stand_anim too. To make this possible, all edges (arrows) must get a name. By using the same name for edges in different state machines, you can indicate you want those edges be taken together at the same time.
To synchronize edges, all edges must get a name. As an edge represents a instantaneous switch, it is best if you can find names for edges that represent a single point in time, like start or touch_down. The rule for synchronization of edges is that each state machine may take an edge with a given name, only if all other state machines that have edges with the same name, also do that. State machines that do not have any edge with that name do nothing, and keep their current state. Since this rule holds for all state machines, edges with a name that occur in several state machines are either not taken, or all state machines involved take the edge.
To make it more concrete, below are the same state machines as above, but edges now also have names.
Example 1
Let's start simple. Assume the animations current state is Crawl_leftarm_anim. From that state, it can take the stop edge to Stand_anim, or the right_crawl edge to Crawl_rightarm_anim. Assume the latter is preferred. The rule about edges says that it can take that edge only when all other state machines with a right_crawl edge also take that edge now. As there are no such other state machines, the condition trivially holds, and the animations current state can be moved to Crawl_rightarm_anim without doing anything with the current state of the game character.
Example 2
The case where both state machines synchronize on an edge is a bit longer, but the steps are the same. Let's consider the Running game character state. From the Running current state, are two edges available. One edge is labeled take_off and leads to the Jumping state. The other edge is labeled stop, leading to the Standing state.
Suppose I want it to take the take_off edge here. The rule about edges says that I can only do that if all other state machines that have a take_off edge anywhere in their description, also take it. That implies that the current state of the animations must be Run_anim (else there is no edge take_off that the animations state machine can take).
Also, the animations state machine must be willing to take the take_off edge, and not the stop edge. Assuming both state machines want to do the take_off edge. There are no other state machines with a take_off edge, and the conclusion is that the edge can be taken, since all state machines with such an edge participate. At that moment, the game character current state moves to Jumping, and the animations current state moves to Fly_anim at the same time.
So far, we have been talking about state machines, with current states, and edges that they can be taken together or alone, based on their name. It's all nice pictures, but it still needs to be connected somehow to the other code. Somewhere you need to make a choice when to take_off.
There are two parts to connecting. The first part is about deciding which edges are available, that is, from the current state of both state machines, which edges can be taken now (separately for each state machine). The second part is about changes in the state of the game character and the animations. When you take the take_off edge, and reach the Fly_anim state, you want the game character to know it flies, and you want the animation engine to display the flying animation. Actions (assignments) need to be performed when a current state changes to make that happen.
Starting with the first part, each edge must 'know' if it is allowed to be taken. This is done by adding conditions to each edge. The additional rule about edges is that the conditions of an edge must hold (must return true) before you can take the edge. Edges without conditions may always be taken (or equivalently, their edges always hold). If you want to write the conditions near the edge on paper, by convention such conditions are near the back of the edge (close to the state that you leave), as the conditions must be checked before you may traverse the edge.
For example, in the Running state of the game character, you could add a JumpButtonPressed() test to the take_off edge. Similarly, the stop edge could get a not SpaceBarPressed() condition. When the game character current state is Running and the player keeps the space bar pressed down, the not SpaceBarPressed() test fails, which means the state machine cannot take the stop edge. Similarly, the JumpButtonPressed() test also fails, as the user did not press the jump key yet. As a result, the game character state machine cannot change its current state, and stays in the Running state. The animation state machine cannot move either (Run_anim state needs co-operation of the game character state machine to get out of the state), and continues to display the running animation.
When the user now presses the jump button (while still holding the space bar), the JumpButtonPressed() test becomes true, and the take_off edge can be taken as far as the game character state machine is concerned. However, since the animations state machine also has a take_off edge, the condition of the latter edge must also yield true. If it does, both edges are taken at the same time, and the current states of the game character becomes Jumping while the animations state machines changes to the Fly_anim state.
The latter additional check in the animations state machine opens useful additional opportunities. Remember we wanted to have smooth animation transitions? In that case, you cannot just switch to a different animation when the user wants. You need to time it such that it happens at exactly the right frame in the animation.
With the latter additional check, that is relatively easy to achieve. Just add a condition to the take_off edge in the animations state machine that it can only change to the next state when the right frame in the running animation is displayed.
When the user presses the jump button, the game character state machine allows taking the take_off edge (JumpButtonPressed() holds), but the same edge in the animation state machine refuses it until the right frame is displayed. As a result, the edge is not taken (the jump button is ignored), until both the jump button is pressed and the right frame is displayed. At that moment, the conditions of both edges hold, and both state machines take their take_off edge, making the game character fly away (until it lands again).
The second part is that moving to a new current state should have an effect in the game. Some code needs to be executed to display a flying animation when you reach Fly_anim.
To achieve that statements are added to an edge. When the conditions of an edge hold, and the other state machines take an edge with the same name as well, you take the edge, and execute the statements. For example, in the animations state machine, you could add the statement StartAnimation(Flying) to the edge named take_off. By convention, such statements are written near the front of the edge (near the arrow head), as you perform them just before you reach the new current state. In this article, only edges have statements. However, there exist a number of extensions, which ease writing of the state machines. You may want to consider adding such extensions. They are discussed below.
When you have several edges leading to the same state, as in the Crawl_leftarm_anim state, you will find that often you need to perform the same code at each edge to that state, for example StartAnimation(LeftCrawl). To remedy this duplication, you can decide to add code to the new current state, which is executed at the moment enter the new state (just after executing the code attached to the edge). If you move common code like the StartAnimation(LeftCrawl) statement to it, it gets run no matter by which edge you arrive there.
A second extension is that sometimes you need to perform some code for every frame while you are in a state. You can add such code in the state as well. Create an OnEveryLoop function for the states that gets called as part of the game loop.
As an example of the latter, imagine that in the Jumping state, the game character must go up a little bit and then descend. You can do this by having a variable dy in the game character code representing vertical speed, and setting it to a small positive value when you enter the jumping state (assuming positive y is up). In the OnEveryLoop function of the jumping state, do
Each loop, the above statements are executed, and the game character will slow down going up, and then descend (faster and faster and faster and ...). The land edge condition should trigger when the game character hits a platform, which resets the dy variable back to 0, and we have touch down.
The state machines are quite useful as method of describing what can happen, and how game character states and animation states relate, but seeing them in action is worth a thousand pictures, if not more. First the algorithm is explained in pseudo-code, a discussion about more realistic implementations follows.
Luckily implementing synchronous state machines is not too difficult. First, you implement the game character state machine and the animations state machines. In the code below, functions GetGameCharacterStateMachine() and GetAnimationsStateMachine() construct both state machines (in the algorithm they are quite empty). Strings are used to denote the states and edge names. There is a function GetFeasibleEdgenames(<state-machine>, <current-state>, <edge-name-list>) that returns a list of edge names that can be taken at this time (by testing conditions of edges with the given names that leave from the current state). There is also a function TakeEdge(<state-machine>, <current-state>, <edge-name>) that takes the edge with the given name in the state machine, performs the assignments, and returns the new current state. The GetCommonNames(<name-list>, <name-list>) returns the edge names that occur in both given lists (like intersection). Finally, len(<name-list>) returns the number of elements in the list (used for testing whether the list is empty).
In the initialization, construct both state machines, and initialize them to their first current state. Also setup lists of shared edge names, and non-shared edge names.
Somewhere in the game loop, you try to advance both state machines.
As synchronizing edges need co-operation from both state machines, they take precedence over non-synchronizing edges in each individual state machine. The gsm_common and asm_common variables contain edge names that each state machine can take. After filtering on the common values with GetCommonNames() the first common synchronizing edge is taken if it exists. If it does not exist, each state machine is tried for edge names that are not synchronized, and if found, the edge is taken.
Note that to take a synchronized edge, the edge name must appear in both gsm_common and asm_common. That means the conditions of both edges are checked and both hold. When you take the edge, TakeEdge performs the assignments of both edges, starting with the game character state machine. This code thus combines both edges, performs all checks, and performs all assignments.
In this example, gsm_names is empty, which means there will never be an edge that is taken by the game character state machine on its own. In the general case however, there will be edge names (and if not, you can simply remove that part of the algorithm).
The algorithm above aims to make the explanation as clear as possible. From a performance point of view, it is horrible or worse.
It is quite tempting to make lots of objects here. For the gsm and asm state machines, this would be a good idea. They can act as container for the GetFeasibleEdgenames and TakeEdge functions. Since these functions have conditions and assignments about the other parts of the game, the containers will need some form of embedding to get access to the variables and functions they use.
A state object would contain only the edge information to the next states, and the assignments to perform. The latter makes each state object unique code-wise. Edges have a similar problem, they contain their name, a reference to the next state, the conditions that must hold before you may take it, and assignments that you perform when you take the edge. The conditions and assignments make again each object unique in code.
One way out of this is to make lots of classes with inline code. Another option is to make arrays with the static data, and use integers for the current states. The condition checks could be dispatched through a switch on the current state. Assignments performed in the new state could also be done in a switch.
The key problem here is finding the common[0] value (if it exists). The algorithm above queries each state machine separately. Instead, you could feed the gsm_common answer into the asm_common computation. The GetCommonNames will never return anything outside the gsm_common set no matter what asm_common contains.
To get fast edge name matching, make edge names an integer value, and return an array of edges that can be taken from the GetFeasibleEdgenames(gsm, current_gsm, shared_names) call. Length of the array is the number of edge names that exist, and edge names that have no valid edge are null. The GetFeasibleEdgenames(asm, current_asm, shared_names) function would need to be renamed, and rewritten to use that array to find a common synchronizing edge name. It can stop at the first match.
If there is no synchronizing edge name, the algorithm uses the same generic GetFeasibleEdgenames and TakeEdge functions to perform a non-synchronizing edge. In a real implementation, you can combine both calls into one function. If you split edges with synchronizing names from edges with non-synchronizing names, you can make a new function that sequentially inspects the latter edges, and if the conditions hold, immediately also take it, and return.
In this article, two state machines are used, one for the game character, and one for the animations. However, there is no fundamental reason why you could not extend the idea to more than two state machines. Maybe you want a state machine to filter player input. The rules do not change, but the implementation gets more involved, as there are more forms of synchronizing events in such a case.
The state machines described in this article are based on automata normally found in Controller design of Discrete Event systems. There is a large body of literature about it, for example
This theory does have edge names (called 'events'), but no conditions or assignments, as they are not embedding the state machines into a context. Conditions and assignments are used in languages/tools like Modelica or Uppaal.
In all, a rather complicated sequence of checks, actions, and assignments that need to be handled. The sequence quickly runs out of hand with a growing number of moves, game states, and animations. Lots of combinations have to be checked. While writing it once is hard enough, if you have to update or modify it later, finding all the right spots to change without missing one, is the second big problem.
By using state machines, it becomes possible to express precisely what may happen in an orderly way. One state machine only describes the animations and their transitions. A second state machine describes user interaction with the game character, and updates the game character state. By keepinh animation state and game character state separate, things get much easier to understand, and to reason about. Later changes also get simpler as it avoids duplication.
While having such state machines on paper is already quite helpful in understanding, there is also a straight forward implementation path, which means you can plug your state machines into the game, and run them.
Audience, or what you should know before reading
This article briefly touches on what state machines are and how they work, before jumping into the topic at hand. If you don't know about state machines, it is probably a good idea to read about them first. The state machines here are somewhat different, but it helps if the state machine concept is not entirely new. The References section below lists some starting points, but there are many more resources available at the all-knowing Internet.
The article concentrates on using state machines for describing allowed behavior, and how the state machines synchronize. While it has an example to demonstrate the ideas, the article does not discuss the environment around the state machines at length. That is, how to make user input and game state available to the state machine condition, or how to start and run animations. The implementation of the synchronizing state machines is also not shown in full detail.
State machines
A state machine is a way to describe behavior (activities that are being done for a while), and how you can switch between different activities. Each activity is called a state. Since this is so awfully abstract, let's try to describe your behavior right now. You are currently reading (this text). Reading is a state. It's an activity that you do for a while. Now suppose you get a phone call. You stop reading, and concentrate on the conversation. Talking on the phone is another activity that you do for a while, a second state. Other states of you are Walking, Running, Sleeping, and a lot more.

The activity that you are doing now is special in the description. The state associated with the current activity is called current state (not indicated in the figure). It is a "you are doing this" pointer.
Having states is nice, but so far it's just a list of activities you can do, and a current state, the activity you are doing right now. What is missing, is structure between the states. You can go from Running directly to Sleeping or to any other activity. It is not a very good description of how activities relate. This is where edges come in. Edges define how you can switch from one state to the next. You can see an edge as an arrow, starting at one state, and pointing to the next state. The rule is that you can only change the current state by following an edge from the current state to the state where the edge leads to. The latter state then becomes the new current state (your new activity).
By adding or removing edges between the states, you can influence how the current state can switch between different activities. For example, if you don't have a Running to Sleeping edge, and add a Running to Showering edge and a Showering to Sleeping edge, you can force the current state through the Showering state while going from Running to Sleeping.

Defining game character behavior
You can apply the same ideas to your game character (or your AI character). Game characters are a lot simpler than real world persons to describe. You can see an example below.

This game character can do just four activities. It can stand (on a platform for example), run, jump, and crawl. The edges say how you can change between states. It shows for example, that you have to go from Crawling to Standing to Running. You cannot go directly from Crawling to Running.
Defining animation sequences
Game character states are kind of obvious, but you can use state machines for a lot more. If you see displaying a (single) animation as an 'activity that is being done for a while' (namely showing all the frames one by one until the end of the animation), you can consider displaying an animation to be a state, and switching between animations an edge, and you can draw a diagram like below.
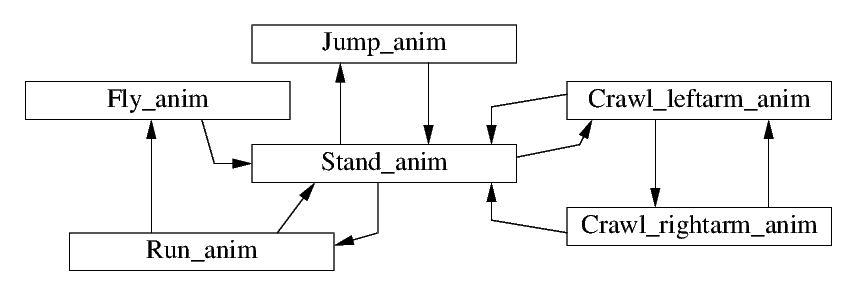
You have a state for each animation, and the current state here is the animation currently playing. Edges define how you can go from one animation to the next. Since you want smooth animation, you only add edges from one animation to the next, where the animations 'fit' (more on the precise timing of this below, when discussing conditions of edges).
If you compare the character states with the animation states, you see there is a lot of overlap, but not entirely. The Crawling character state has been expanded to Crawl_leftarm_anim (crawling with your left arm on the floor), and Crawl_rightarm_anim (crawling with your right arm on the floor). From the standing animation you always start with Crawl_leftarm_anim, and you can go back and forth between the left arm and right arm animation, thus slowly crawling across the screen. The Jumping character state has also been split, if you run before jumping, you get a different (flying) animation.
Each state machine should only care about its own data. The game character state machine handles user input, and updates game character state; the animations state machine deals with animations, frame rates, and frames. The computer handles synchronization between both state machines, as discussed below.
Synchronizing behavior
So far so good. We have a state machine describing how the game character behaves, and we have a state machine describing how to play animation sequences.
Now it would be quite useful if the current state of the game character and the current state of the animations match in some way. It looks very weird if the game character state is Standing, while the current animation displays Running_anim. You want to display the running animation only when the game character state is Running too, display one of the crawling animations when the game character state is Crawling, and so on. In other words, both state machines must be synchronized in some way.
The simplest form of synchronization is fully synchronized on state. In that case, each game character state has one unique animation state. When you change the game character state, you also change the animation state in the same way. In fact, if you have this, the game character state machine and the animation state machine are exactly the same! (The technical term is isomorphic.) You can simply merge both state machines into one, and get a much simpler solution.
However, in the example, full synchronization on state fails. There are two animation states for crawling, and the Fly_anim does not even have a game character state in the example.
What is needed in the example is a bit more flexibility. The animation state machine should for example be allowed to switch between the Crawl_leftarm_anim and Crawl_rightarm_anim animations without bothering the game character state machine about it. Similarly, the Jumping state should not care whether a Fly_anim or Jump_anim is displayed. On the other hand, if you go from Running to Standing in the game character state machine, you do want the animation state machine to go to Stand_anim too. To make this possible, all edges (arrows) must get a name. By using the same name for edges in different state machines, you can indicate you want those edges be taken together at the same time.
Edge synchronization
To synchronize edges, all edges must get a name. As an edge represents a instantaneous switch, it is best if you can find names for edges that represent a single point in time, like start or touch_down. The rule for synchronization of edges is that each state machine may take an edge with a given name, only if all other state machines that have edges with the same name, also do that. State machines that do not have any edge with that name do nothing, and keep their current state. Since this rule holds for all state machines, edges with a name that occur in several state machines are either not taken, or all state machines involved take the edge.
To make it more concrete, below are the same state machines as above, but edges now also have names.


Example 1
Let's start simple. Assume the animations current state is Crawl_leftarm_anim. From that state, it can take the stop edge to Stand_anim, or the right_crawl edge to Crawl_rightarm_anim. Assume the latter is preferred. The rule about edges says that it can take that edge only when all other state machines with a right_crawl edge also take that edge now. As there are no such other state machines, the condition trivially holds, and the animations current state can be moved to Crawl_rightarm_anim without doing anything with the current state of the game character.
Example 2
The case where both state machines synchronize on an edge is a bit longer, but the steps are the same. Let's consider the Running game character state. From the Running current state, are two edges available. One edge is labeled take_off and leads to the Jumping state. The other edge is labeled stop, leading to the Standing state.
Suppose I want it to take the take_off edge here. The rule about edges says that I can only do that if all other state machines that have a take_off edge anywhere in their description, also take it. That implies that the current state of the animations must be Run_anim (else there is no edge take_off that the animations state machine can take).
Also, the animations state machine must be willing to take the take_off edge, and not the stop edge. Assuming both state machines want to do the take_off edge. There are no other state machines with a take_off edge, and the conclusion is that the edge can be taken, since all state machines with such an edge participate. At that moment, the game character current state moves to Jumping, and the animations current state moves to Fly_anim at the same time.
Connecting to the rest of the game
So far, we have been talking about state machines, with current states, and edges that they can be taken together or alone, based on their name. It's all nice pictures, but it still needs to be connected somehow to the other code. Somewhere you need to make a choice when to take_off.
There are two parts to connecting. The first part is about deciding which edges are available, that is, from the current state of both state machines, which edges can be taken now (separately for each state machine). The second part is about changes in the state of the game character and the animations. When you take the take_off edge, and reach the Fly_anim state, you want the game character to know it flies, and you want the animation engine to display the flying animation. Actions (assignments) need to be performed when a current state changes to make that happen.
Edge conditions
Starting with the first part, each edge must 'know' if it is allowed to be taken. This is done by adding conditions to each edge. The additional rule about edges is that the conditions of an edge must hold (must return true) before you can take the edge. Edges without conditions may always be taken (or equivalently, their edges always hold). If you want to write the conditions near the edge on paper, by convention such conditions are near the back of the edge (close to the state that you leave), as the conditions must be checked before you may traverse the edge.
For example, in the Running state of the game character, you could add a JumpButtonPressed() test to the take_off edge. Similarly, the stop edge could get a not SpaceBarPressed() condition. When the game character current state is Running and the player keeps the space bar pressed down, the not SpaceBarPressed() test fails, which means the state machine cannot take the stop edge. Similarly, the JumpButtonPressed() test also fails, as the user did not press the jump key yet. As a result, the game character state machine cannot change its current state, and stays in the Running state. The animation state machine cannot move either (Run_anim state needs co-operation of the game character state machine to get out of the state), and continues to display the running animation.
When the user now presses the jump button (while still holding the space bar), the JumpButtonPressed() test becomes true, and the take_off edge can be taken as far as the game character state machine is concerned. However, since the animations state machine also has a take_off edge, the condition of the latter edge must also yield true. If it does, both edges are taken at the same time, and the current states of the game character becomes Jumping while the animations state machines changes to the Fly_anim state.
The latter additional check in the animations state machine opens useful additional opportunities. Remember we wanted to have smooth animation transitions? In that case, you cannot just switch to a different animation when the user wants. You need to time it such that it happens at exactly the right frame in the animation.
With the latter additional check, that is relatively easy to achieve. Just add a condition to the take_off edge in the animations state machine that it can only change to the next state when the right frame in the running animation is displayed.
When the user presses the jump button, the game character state machine allows taking the take_off edge (JumpButtonPressed() holds), but the same edge in the animation state machine refuses it until the right frame is displayed. As a result, the edge is not taken (the jump button is ignored), until both the jump button is pressed and the right frame is displayed. At that moment, the conditions of both edges hold, and both state machines take their take_off edge, making the game character fly away (until it lands again).
Edge assignments
The second part is that moving to a new current state should have an effect in the game. Some code needs to be executed to display a flying animation when you reach Fly_anim.
To achieve that statements are added to an edge. When the conditions of an edge hold, and the other state machines take an edge with the same name as well, you take the edge, and execute the statements. For example, in the animations state machine, you could add the statement StartAnimation(Flying) to the edge named take_off. By convention, such statements are written near the front of the edge (near the arrow head), as you perform them just before you reach the new current state. In this article, only edges have statements. However, there exist a number of extensions, which ease writing of the state machines. You may want to consider adding such extensions. They are discussed below.
When you have several edges leading to the same state, as in the Crawl_leftarm_anim state, you will find that often you need to perform the same code at each edge to that state, for example StartAnimation(LeftCrawl). To remedy this duplication, you can decide to add code to the new current state, which is executed at the moment enter the new state (just after executing the code attached to the edge). If you move common code like the StartAnimation(LeftCrawl) statement to it, it gets run no matter by which edge you arrive there.
A second extension is that sometimes you need to perform some code for every frame while you are in a state. You can add such code in the state as well. Create an OnEveryLoop function for the states that gets called as part of the game loop.
As an example of the latter, imagine that in the Jumping state, the game character must go up a little bit and then descend. You can do this by having a variable dy in the game character code representing vertical speed, and setting it to a small positive value when you enter the jumping state (assuming positive y is up). In the OnEveryLoop function of the jumping state, do
y += dy; // Update y position of the character.
dy--; // Vertical speed decreases.
Each loop, the above statements are executed, and the game character will slow down going up, and then descend (faster and faster and faster and ...). The land edge condition should trigger when the game character hits a platform, which resets the dy variable back to 0, and we have touch down.
Implementation
The state machines are quite useful as method of describing what can happen, and how game character states and animation states relate, but seeing them in action is worth a thousand pictures, if not more. First the algorithm is explained in pseudo-code, a discussion about more realistic implementations follows.
Luckily implementing synchronous state machines is not too difficult. First, you implement the game character state machine and the animations state machines. In the code below, functions GetGameCharacterStateMachine() and GetAnimationsStateMachine() construct both state machines (in the algorithm they are quite empty). Strings are used to denote the states and edge names. There is a function GetFeasibleEdgenames(<state-machine>, <current-state>, <edge-name-list>) that returns a list of edge names that can be taken at this time (by testing conditions of edges with the given names that leave from the current state). There is also a function TakeEdge(<state-machine>, <current-state>, <edge-name>) that takes the edge with the given name in the state machine, performs the assignments, and returns the new current state. The GetCommonNames(<name-list>, <name-list>) returns the edge names that occur in both given lists (like intersection). Finally, len(<name-list>) returns the number of elements in the list (used for testing whether the list is empty).
In the initialization, construct both state machines, and initialize them to their first current state. Also setup lists of shared edge names, and non-shared edge names.
gsm = GetGameCharacterStateMachine(); asm = GetAnimationsStateMachine(); // Set up current states. current_gsm = "Standing"; current_asm = "Stand_anim"; // Set up lists of edge names. shared_names = ["take_off", "land", "stop", "jump", "run", "crawl"]; gsm_names = []; // gsm has no non-shared edge names asm_names = ["left_crawl", "right_crawl"];
Somewhere in the game loop, you try to advance both state machines.
gsm_common = GetFeasibleEdgenames(gsm, current_gsm, shared_names);
asm_common = GetFeasibleEdgenames(asm, current_asm, shared_names);
common = GetCommonNames(gsm_common, asm_common);
if len(common) > 0 then
current_gsm = TakeEdge(gsm, current_gsm, common[0]); // Found a synchronizing edge, take it
current_asm = TakeEdge(asm, current_asm, common[0]); // and update the current states.
else
gsm_only = GetFeasibleEdgenames(gsm, current_gsm, gsm_names);
if len(gsm_only) > 0 then
current_gsm = TakeEdge(gsm, current_gsm, gsm_only[0]); // Take edge in game character only.
end
asm_only = GetFeasibleEdgenames(asm, current_asm, asm_names);
if len(asm_only) > 0 then
current_asm = TakeEdge(asm, current_asm, asm_only[0]); // Take edge in animations only.
end
end
As synchronizing edges need co-operation from both state machines, they take precedence over non-synchronizing edges in each individual state machine. The gsm_common and asm_common variables contain edge names that each state machine can take. After filtering on the common values with GetCommonNames() the first common synchronizing edge is taken if it exists. If it does not exist, each state machine is tried for edge names that are not synchronized, and if found, the edge is taken.
Note that to take a synchronized edge, the edge name must appear in both gsm_common and asm_common. That means the conditions of both edges are checked and both hold. When you take the edge, TakeEdge performs the assignments of both edges, starting with the game character state machine. This code thus combines both edges, performs all checks, and performs all assignments.
In this example, gsm_names is empty, which means there will never be an edge that is taken by the game character state machine on its own. In the general case however, there will be edge names (and if not, you can simply remove that part of the algorithm).
Real implementations
The algorithm above aims to make the explanation as clear as possible. From a performance point of view, it is horrible or worse.
It is quite tempting to make lots of objects here. For the gsm and asm state machines, this would be a good idea. They can act as container for the GetFeasibleEdgenames and TakeEdge functions. Since these functions have conditions and assignments about the other parts of the game, the containers will need some form of embedding to get access to the variables and functions they use.
A state object would contain only the edge information to the next states, and the assignments to perform. The latter makes each state object unique code-wise. Edges have a similar problem, they contain their name, a reference to the next state, the conditions that must hold before you may take it, and assignments that you perform when you take the edge. The conditions and assignments make again each object unique in code.
One way out of this is to make lots of classes with inline code. Another option is to make arrays with the static data, and use integers for the current states. The condition checks could be dispatched through a switch on the current state. Assignments performed in the new state could also be done in a switch.
The key problem here is finding the common[0] value (if it exists). The algorithm above queries each state machine separately. Instead, you could feed the gsm_common answer into the asm_common computation. The GetCommonNames will never return anything outside the gsm_common set no matter what asm_common contains.
To get fast edge name matching, make edge names an integer value, and return an array of edges that can be taken from the GetFeasibleEdgenames(gsm, current_gsm, shared_names) call. Length of the array is the number of edge names that exist, and edge names that have no valid edge are null. The GetFeasibleEdgenames(asm, current_asm, shared_names) function would need to be renamed, and rewritten to use that array to find a common synchronizing edge name. It can stop at the first match.
If there is no synchronizing edge name, the algorithm uses the same generic GetFeasibleEdgenames and TakeEdge functions to perform a non-synchronizing edge. In a real implementation, you can combine both calls into one function. If you split edges with synchronizing names from edges with non-synchronizing names, you can make a new function that sequentially inspects the latter edges, and if the conditions hold, immediately also take it, and return.
More state machines
In this article, two state machines are used, one for the game character, and one for the animations. However, there is no fundamental reason why you could not extend the idea to more than two state machines. Maybe you want a state machine to filter player input. The rules do not change, but the implementation gets more involved, as there are more forms of synchronizing events in such a case.
References
The state machines described in this article are based on automata normally found in Controller design of Discrete Event systems. There is a large body of literature about it, for example
Introduction to Discrete Event Systems, second edition
by Christos G. Cassandras and Stéphane Lafortune
Springer, 2008
This theory does have edge names (called 'events'), but no conditions or assignments, as they are not embedding the state machines into a context. Conditions and assignments are used in languages/tools like Modelica or Uppaal.
- www.openmodelica.org
- (wikipedia) Modelica
- www.uppaal.org
- (gamedev) State Machines in Games States as rooms (adventure), character and object behavior, activities marrying characters and objects state changes.
- (gamedev) Finite State Machines and Regular Expressions State machine explanation, regular expressions, NFA, DFA, NFA-DFA (Thompson).
- (wikipedia) Graph isomorphism Isomorphism between graphs, thestate machines are a little more complicated as edges are directed in our situation.
- (stackexchange) Isomorphism between state machines
Versions
- Post that inspired writing this article (August 11, 2015) The best way to manage sprite sheet animations?